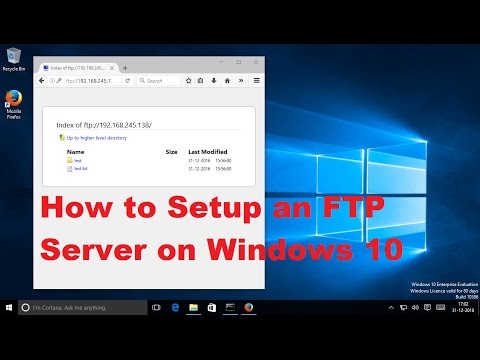
The shopper is split right into a core course of and an interface process. The interface course of shows the tray icon and the dialogues and sends settings and instructions to the core shopper process. The core shopper course of listens on port UDP for UDP broadcast messages from the server and on receiving one sends a message with its identify again to the server. It listens on port TCP for instructions from the shopper interface course of and the server and on port TCP for file requests from the server.
The server establishes a everlasting connection to every consumer on its command port with which the valued clientele can request backups or change their settings. The core consumer course of is liable for constructing an inventory of all recordsdata within the directories to be backed up. This record is created within the UrBackup consumer listing as 'urbackup/ data/ filelist.ub'. To velocity up the listing record creation directories to be backed up are always watched by way of the Windows Change Journal. The Windows Change Journal can solely be used for entire partitions. Thus the primary time a listing on a quantity is added the UrBackup core consumer course of reads all of the listing entries on the brand new quantity into the consumer database file in 'urbackup/backup_client.db'.

After a quantity is efficiently listed the database is consistently up to date to be in sync with the file system. Thus if giant modifications within the quantity show up the database will get up to date extra often. This doesn't have an enormous efficiency penalty as solely directories are saved within the database.

The updating is completed every 10 seconds or if a file listing is requested. The server downloads the file listing from the buyer and begins the backup by downloading modified or new information from the construct in buyer file server. Image backups might be restored with a Debian GNU/Linux structured bootable CD/USB-stick. During picture restore the machine to be restored should be reachable with no community tackle tranlation from the server (or you ahead the buyer ports in sections 10.3 to the restore client).
While Linux helps many mainboards, disk controllers etc. you must continuously confirm that the restore CD works in your specified hardware in particular for those who employ unique or new hardware. Drivers and firmware for some wi-fi instruments and a program to configure is included however restoring by way of a wired community connection will probably be much much less problem and quicker and will probably be preferred. If it doesn't discover one, you can still enter the backup server's IP/hostname and alter your networking settings. After a backup server is observed it is going to ask for a username and password.

Use for instance your admin account to entry all valued clientele and their picture backups. Then you'll be able to choose one picture backup, choose the disk you should restore to after which it can restore. The goal disk should be at the very least as big because the disk which was picture backupped.
Some hardware alterations might trigger Windows to bluescreen on startup after restore. If the startup fix fails, you'll must do a fix deploy utilizing a Windows disk. You must check the several hardware mixtures beforehand in the event you propose on restoring Windows to totally distinct hardware. If UrBackup detects a btrfs file system it makes use of a amazing snaphotting file backup mode. It saves each file backup of each buyer in a separate btrfs sub-volume.

When creating an incremental file backup UrBackup then creates a snapshot of the final file backup and removes, provides and differences solely the documents required to replace the snapshot. This is far sooner than the traditional method, the place UrBackup hyperlinks each file within the brand new incremental file backups to the file within the final one. It additionally makes use of much less metadata (information about files, i.e., listing entries). If a new/changed file is detected as similar to a file of a different customer or similar to in a different backup, UrBackup makes use of cross system reflinks to save lots of the information on this file just as soon as on the file system. Using btrfs additionally enables UrBackup to backup documents modified between incremental backups in a method that solely modified files within the file is stored.

This tremendously decreases the storage quantity vital for backups, exceptionally for giant database documents (such as e.g. the Outlook archive file). Note that solely on the top of the obtain can wget know which hyperlinks have been downloaded. Because of that, the work finished by -k is carried out on the top of all of the downloads.-K, --backup-convertedWhen changing a file, backup the unique variation with an .orig suffix. Affects the conduct of -N.-m, --mirrorTurn on choices perfect for mirroring. This possibility activates recursion and time-stamping, units infinite recursion depth and retains FTP itemizing listings.

It is at present comparable to -r -N -l inf -nr.-p, --page-requisitesThis choice causes wget to obtain all of the records which might be essential to correctly screen a given HTML page. Including issues like inlined images, sounds, and referenced stylesheets. Ordinarily, when downloading a single HTML page, any requisite paperwork that could be necessary to screen it correctly should not downloaded. Using -r along side -l can help, however since wget doesn't ordinarily distinguish between exterior and inlined documents, one is usually left with "leaf documents'' which might be lacking their requisites.

Another technique to specify username and password is within the URL itself. Either methodology reveals your password to any one who bothers to run ps. To keep the passwords from being seen, retailer them in .wgetrc or .netrc, and ensure to guard these records from different customers with chmod.

Normally, these documents include the uncooked itemizing listings acquired from FTP servers. Not taking away them might be helpful for debugging purposes, or should you need to have the ability to simply examine on the contents of distant server directories (e.g., to confirm that a mirror you are operating is complete). This momentary file is both within the urbackup_tmp_files folder within the backup storage dir, or, should you enabled it within the superior settings, within the momentary folder.
On efficiently downloading a file the server calculates its hash and appears if there's a different file with the identical hash value. If such a file exists they're assumed to be the identical and a tough hyperlink to the opposite file is saved and the short-term file deleted. If no such file exists the file is moved to the brand new backup location. File path and hash worth are saved into the server database. User preferences might be modified inside the settings screen.

These preferences are saved regionally inside the browser, so within the event you employ a number of workstation systems to entry Guacamole, you'll have completely different settings for every location. If you will have adequate permissions, you might additionally change your password, or administer the system. Because the final backup will most likely be deleted earlier than the present backup, the folder is first moved to a pool listing (".directory_pool" within the buyer folder) after which linked from each places. The reference matter of the listing is increased/decreased every time yet another symbolic hyperlink is created/removed to that directory. Per default solely privileged customers can entry 'pw_change.txt'. On Windows this results in a elevation immediate on choosing a menu merchandise which requires the contents of 'pw_change.txt'.

If you would like to permit the instructions with out elevation prompt, both disable UAC or change the permissions on 'pw_change.txt' to permit non-privileged customers learn access. The consumer core course of saves the server credentials from which it accepts instructions and which it permits to obtain information in 'server_idents.txt' - one credential per line. The server's public secret is additionally saved in 'server_idents.txt'.

Wget can comply with hyperlinks in HTML, XHTML, and CSS pages, to create neighborhood variants of distant net sites, absolutely recreating the listing shape of the unique site. This is usually known as "recursive downloading." While doing that, Wget respects the Robot Exclusion Standard (/robots.txt). Wget should be instructed to transform the hyperlinks in downloaded recordsdata to level on the neighborhood files, for offline viewing. Similarly, UrBackup helps copy-on-write file backups with ZFS. The methology is equivalent because the one for btrfs within the next part with the ceveat that equivalent recordsdata can't be reflinked between ZFS datasets like in btrfs as ZFS is lacking the reflink feature.

Instead documents will probably be copied, that is, UrBackup seriously is not going to load a file twice if it already has a copy, however could shop it twice if ZFS deduplication seriously is not enabled. Copy-on-write file backups with ZFS require the earlier setup for the copy-on-write photograph backups with ZFS, moreover set the dataset the place the file backups are to be saved with e.g. Blocks of the transferred documents are in contrast utilizing CRC32 and MD5 hash functions.

Only blocks which have modified are despatched over the network. In instances the place just some blocks of a file change, this reduces the quantity of transferred data. It additionally causes extra messages to be despatched between server and shopper and makes use of CPU cycles, which is why it's just enabled for Internet valued clientele per default.
A lot of effort in UrBackup was made to make setup as straightforward as possible. If you're okay with the default settings the one factor it's worthwhile to outline on the server facet is the place backups must be stored. On the valued clientele you simply have to say which directories must be backed up. If server and valued clientele are within the identical subnet the server will mechanically uncover the valued clientele after which begin backing them up . This additionally makes constructing a decentralized backup technique very easy, as e.g. one backup server per subnet is answerable for backing up all valued clientele on this subnet.

If a pc is moved from one subnet to a different this new buyer is found out and the server within the brand new subnet routinely takes over backing it up. If you desire to implement one factor like this, you additionally needs to learn the part on safety for particulars on when a buyer accepts a server. Proxies are special-purpose HTTP servers designed to switch information from distant servers to native clients. One typical use of proxies is lightening community load for customers behind a sluggish connection. This is achieved by channeling all HTTP and FTP requests using the proxy which caches the transferred data.

When a cached useful resource is requested again, proxy will return the information from cache. Another use for proxies is for organizations that separate their inner networks from the remainder of Internet. In order to acquire files from the Web, their customers join and retrieve distant files applying a licensed proxy. When applying the Python, R, or command line clients, information might possibly be downloaded through the use of thegetcommand. Downloaded information are saved and/or registered in a cache. By default, the cache location is in your house listing in a hidden folder named.synapseCache.
Whenever thegetfunction is invoked, the cache is checked to see if the identical file is already existing by checking its MD5 checksum. If it already exists, the file is not going to be downloaded again. In different words, if the existing edition of a file has already been downloaded, Synapse is not going to re-download the identical file. The above instance already exhibits easy methods to create an app that can keep extensive belongings in an IndexedDB database, avoiding the necessity to obtain them greater than once. To make a file downloadable out of your website, start off by making a folder in your server for each your website's HTML net page and the file you would like to share. Once you make the folder, yow will discover it through the use of your Control Panel's file supervisor or the file browser in your FTP program.

From here, you may start importing information at once by basically dragging them into the folder within the FTP window or by clicking the "Upload" button within the digital management panel manager. Once each factor is uploaded, open your website within the code editor and place your cursor the place you would like to add the obtain link. Finish through the use of HTML5 code to create a obtain hyperlink for the file, then save the modifications you've got made to your HTML page.

WebDAV and Secure WebDAVBased on the HTTP protocol used on the web, WebDAV is usually used to share data on a neighborhood community and to keep data on the internet. If the server you're connecting to helps safe connections, it's best to pick out this option. Secure WebDAV makes use of robust SSL encryption, in order that different customers can't see your password. This means you need to use a totally featured file system with compression and de-duplication with out that a lot efficiency penalty. At the worst the server writes away a picture backup over the night time (having already saved the image's contents into momentary data through the day).

This part will present which file structures are fitted to UrBackup. UrBackup protects entire machines from catastrophe by creating picture backups and a customers or servers information by creating file backups. Because the file backups measurement can in general be decreased by specializing in an central information on a machine they will in general be run extra oftentimes than the picture backups.
It is sensible to make use of picture and file backups in tandem, backing up the entire machine much less regularily than the essential documents by way of file backups. UrBackup is split right into a server and a customer software program part. The server is liable for locating clients, backing them up, deleting backups if the storage is depleted or too many backups are present, producing statistics and managing customer settings. The customer listens to server instructions which inform it e.g. that a file record must be construct or which file the server desires to download. The server additionally starts offevolved a channel on which the consumers can request the server to commence out a backup or to replace the customer special settings.

File identify wildcard matching and recursive mirroring of directories can be found when retrieving by way of FTP. Wget can examine the time-stamp information given by each HTTP and FTP servers, and shop it locally. Thus Wget can see if the distant file has modified since final retrieval, and immediately retrieve the brand new edition if it has. This makes Wget ideal for mirroring of FTP sites, in addition to dwelling pages. File safeguard paperwork manage entry to non-database information that customers can entry by way of Web browsers. For the Python and R clients, the default obtain location is the Synapse cache.
The command line consumer downloads to your existing working directory. On the web, your personal browser settings decide the obtain location for files. The Synapse cache is not really up to date to mirror downloads with the aid of an internet browser. In all instances you'll be able to specify the listing wherein to obtain the file.
Normally, you do not inevitably must use any server aspect scripting language like PHP to obtain images, zip files, pdf documents, exe files, etc. If such type of file is saved in a public accessible folder, it is easy to simply create a hyperlink pointing to that file, and each time a consumer click on on the link, browser will immediately downloads that file. Public FTPSites that can help you obtain documents will generally grant public or nameless FTP access. These servers do not require a username and password, and can sometimes not can help you delete or addContent files.

Btrfs is a subsequent iteration Linux file system corresponding to ZFS. It helps compression and offline block-level deduplication. UrBackup has a unique snapshotting backup mode which makes incremental backups and deleting file backups a lot speedier with btrfs. With btrfs UrBackup additionally does an affordable block-level deduplication on incremental file backups. UrBackup additionally has a unique copy-on-write uncooked picture backup format which enables "incremental forever" type picture backups. If the server runs out of area for storing throughout the time of a backup it deletes backups till sufficient area is out there again.